Industry news
AI Research – Predicting Article Reading Time Based on Words Used in the Text


This week we have something special to share: research findings from Twipe’s very own Hannes Buseyne, AI & Software Engineer. He has created an AI algorithm to answer the question “Can AI Predict Reading Time Based on the Words in the Text?” Using a Linear Support Vector Machine algorithm, we are then able to determine the words in articles that lead to the highest and lowest average reading time. The report on this initiative is very interesting, both for its findings applicable for publishers, as well as showing how to write a similar algorithm to determine the most (and least) engaging words for your own readers.
How to Create Your Own Algorithm
In this report you will find a guide for creating your own analysis of data to better understand what your readers like. The report also serves as an introduction to the buzzword of ‘Artificial Intelligence’. Knowing how the computer sees things gives a better understanding of the concept of AI. Topics such as what exactly is meant by Artificial Intelligence, an introduction to machine learning algorithms, and how to construct your own data set are covered.
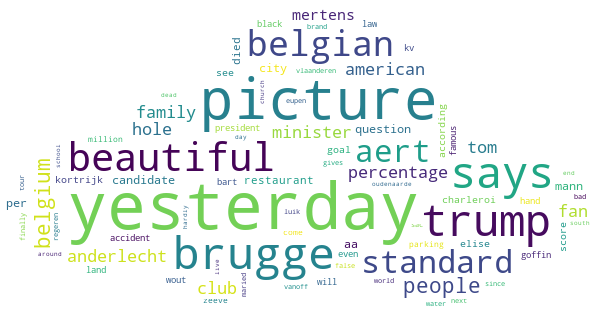
Most Engaging Words
The algorithm shows that the word “yesterday” has a high average reading time, which highlights the importance of recency for reader engagement. In the test case of a Belgian newspaper, the algorithm showed how engaging readers found football-related words–something that is useful for any newspaper to know about its own readers.
For other engaging words to be aware of, plus the least engaging news section, make sure to download the full 8 page report.
You can also learn more about this project on Twipe’s GitHub account.
Other Blog Posts



Stay on top of the game
Join our community of industry leaders. Get insights, best practices, case studies, and access to our events.
"(Required)" indicates required fields