“Today in history”: how AI helps to monetize evergreen archive content at Ouest France
“Today in history” has been the inspiration for a 2 year collaborative research project between Ouest-France and Twipe. The project aimed to explore the potential of a format like “This day in history” at scale. Today we share a summary of this unique and proprietary research and dive into key achievements and top 5 learnings.
“What happened today in history?”
“Today in history”. This engaging content format introduced by Facebook and Apple Photos, inspired Jean-Pierre Besnard, Project & Incubation Manager at Ouest-France, to explore a similar idea. Would it be possible to identify from the large Ouest-France archive evergreen articles easily? And what could be the value of republishing these evergreens automatically? Would readers appreciate such content? And could this be a driver for extra revenues for the largest newspaper in France?
When we met Jean-Pierre during one of our visits in Rennes, he had already done a first small scale test by republishing “Today in history” archive articles on one of the 54 local news sites of the group. The early results were encouraging in terms of reader engagement, but the sheer size of the Ouest-France archive, which includes over 30 million articles, made it impossible for any human to identify and select relevant archive articles for republishing at local and regional level.
We had an interesting exchange about our experience with the JAMES Your Digital Butler project. The machine learning of JAMES was able to select every day a plate of engaging content for the readers of The Times. The opportunity to combine forces for a joint research and innovation project on the subject was quickly clear. We involved as well the French specialist in language processing Syllabs, who brought their expertise on content enrichment. We kicked off the 18 months project in August 2018.
During the project we have worked collaboratively with journalists, product and data science teams. The main achievements of the “Today in history” project are summarised below:
- The content monetization predictive score was introduced at scale. This is a combined metric composed of a static element which indicates the intrinsic lifetime value of the article and a dynamic score, which indicates the relevance of the content within the current news context.
- More than 30 million archive articles were tagged. Each article within the Ouest France archive has received a content monetization predictive score, highlighting its evergreen potential to generate engagement through republishing.
- 50% of relevant articles were selected for republication. Of the articles with a high evergreen score, half got selected by journalists for republication.
- Over 500 articles have been republished. Some articles were selected by a journalist and others selected by the algorithm. Republished articles generate strong reader engagement, when well selected and positioned within the news content of the day.
- “Today in History” has been rolled out in all regional newsrooms. We built an internal search engine based on the Content Monetization Predictive score. This allows the newsroom to select and re-publish evergreen content with a couple of clicks.
Republished articles selected by either journalists, readers or the Content Monetization Prediction algorithm have been exposed to Ouest-France audience from various regions.

From studying the results of this research, we have extracted 5 key learnings on archive content monetization.
Learning 1: republishing evergreen articles from the archive generates significant reader engagement
Throughout the entire project over 500 articles have been republished and the impact on reader engagement has been measured and assessed. These experiments demonstrate that republishing the right articles does lead to higher reader engagement, particularly at a local level. In some cases, republished articles performed much better than newly published articles.
The best scoring articles typically had a very strong image, relate to a local and important event such as a storm or flood and involve a (local) celebrity. Lower performing articles relate to new technology introductions, local sports events with little lasting value or topics from a recent past.
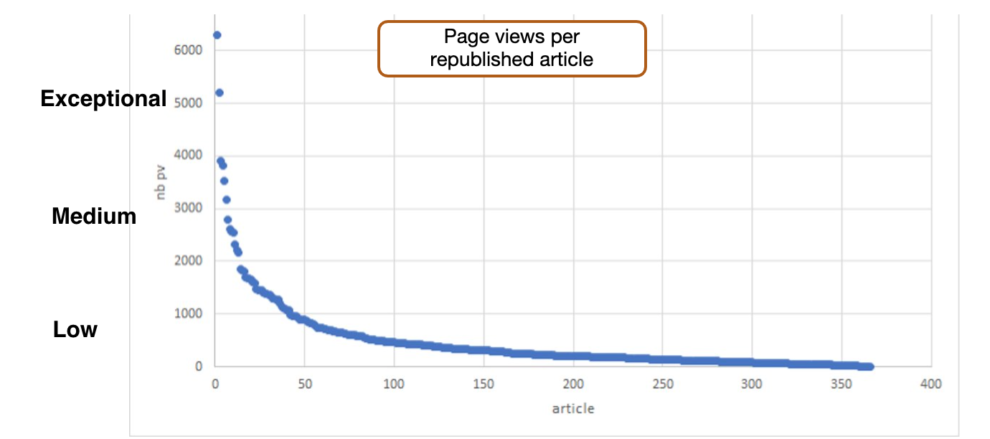
Learning 2: less than 10% of the total archive content pool has “Today in history” value
Selecting the evergreen articles out of a 30 million article content pool isn’t an easy task. We decided to address this key issue from 3 different angles. We first asked journalists to select archive articles for republication. In parallel we developed a set of machine learning and AI algorithms. Finally we involved readers to assess the relevance of articles for republication.
Firstly, journalists at Ouest-France analysed a random set of 1000 archive articles and labelled them in terms of likelihood to be a suitable candidate to republish. On average, 8.5% of articles were selected for republication by journalists.
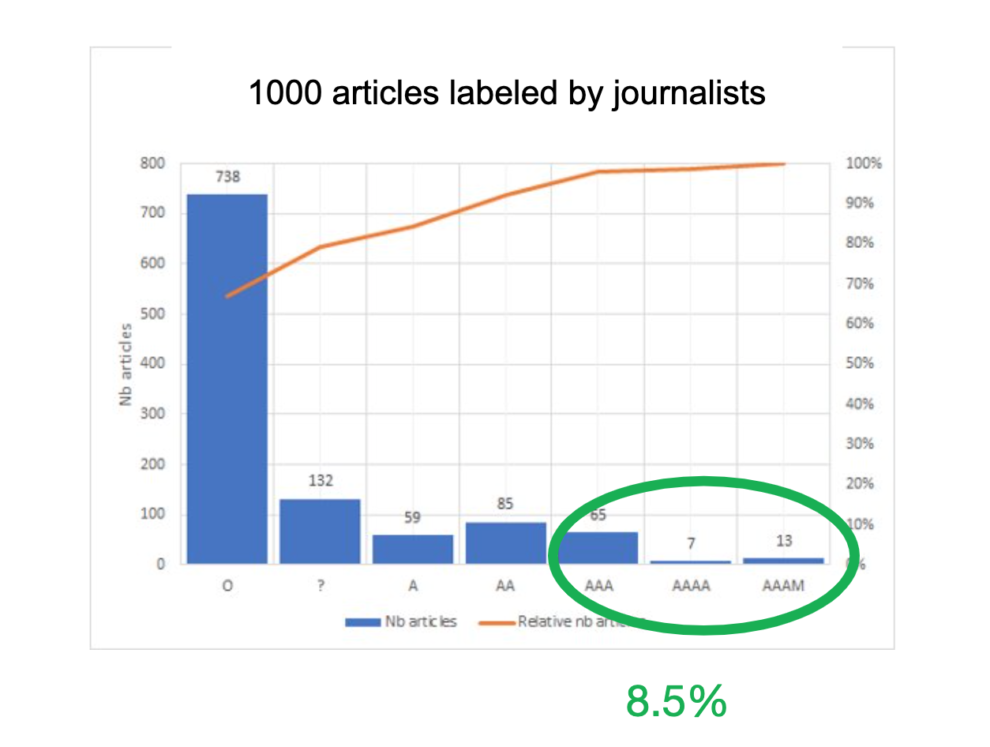
In parallel our data science and AI team used machine learning to create algorithms that could give each article a predictive score, highlighting its evergreen potential to generate engagement through republishing. The predictive republish score is composed of 2 elements. First, a static element which indicates the intrinsic lifetime value of the article. This was based on a number of factors – including the original publication date, the ‘Wikipedia Popularity level’ of persons or named entities involved, the locations talked about and many other items. Second, a dynamic score, which indicates the relevance of the content within the current news context. The dynamic part is recalculated on a rolling time horizon and relates the content to trending news topics.
Ouest France also asked readers to directly contribute to the project via crowdsourcing. Selected readers were presented with archived content and asked to select if certain articles were of interest, or not. With this experiment we found that even a fairly large group of 100 readers were not any better at predicting suitable articles than only 1-2 journalists.
Learning 3: artificial intelligence allows a 5x efficiency gain to identify “Today in history” articles
From the articles with a high score by the algorithms, 46% were selected by journalists for republication. Using the algorithms we were able to surface the right articles almost 5 times faster than journalists working independently. This was perceived as a large benefit by the newsroom. It provided ‘low effort content’ on days or moments with few newsworthy articles. Additionally, it inspired the newsroom to write about new past topics or document the context for other stories.
Not all articles suggested by the algorithm were good fit for re-publishing. Some articles related to people, who have become controversial in the local community. Other articles related to major sports events from the past, but with little relevance today. Finally, articles with good content, but without a quality picture were also not chosen by the editorial team.
Learning 4: be extremely clear to the reader when publishing “Today in history” articles
When republishing the articles on the website, readers have to have a clear indication about the source. During the project, various enhancements have been applied. We added specific elements to the title (e.g. hereunder “RETRO 2006”). We put a label on the image and ended the article with a clear mention of the archives as the source.

Learning 5: leverage the strengths of partners in collaborative innovation
In this project, 3 partners were involved. Each of the partners had a clear focus area and strong contribution to the “Today in history” project.
- Ouest France was in charge of providing access to the content. They offered editorial support, developing an internal search engine and setting up an internal data lake
- Syllabs was focused on enriching the archived content with named entities and emotional affect
- Twipe was in charge of project definition, experiment definition and development of machine learning and Artificial Intelligence (AI) algorithms
Together with Twipe, we have been able to enrich our content archive. We extended our data lake and deployed an internal search engine in all newsrooms. Most importantly, we have proven that we can leverage our archive to offer our readers an engaging experience.
Jean-Pierre Besnard, Project & Incubation Manager, Ouest-France
Do you have a research or innovation idea you would like to explore? Contact us!
Product and technology innovation is high on the agenda of many publishers. At Twipe we have a long history of collaborating with publishers and academia. We have a keen interest in research or co-development projects related to reader engagement, machine learning, artificial intelligence and habit formation. Let us know your idea and explore how we can jointly bring it alive.
In our earliest days we developed new editions DS Avond (with Mediahuis) and L’édition du Soir (with Ouest France). A research project together with Mediahuis resulted in the creation of the EngageReaders ePaper analytics platform. Through co-development with The Times of London we are building JAMES – the personalised newsletters platform.
Contact our Innovation & Incubation Team to explore joint innovation projects together.
—-
Contributors: Simon Robben, Jean-Pierre Besnard, Dana Nastase, Danny Lein and Tom Mann.
Other Blog Posts



Stay on top of the game
Join our community of industry leaders. Get insights, best practices, case studies, and access to our events.
"(Required)" indicates required fields